Advanced Quantitative Economics with Python
Optimal Taxation with State-Contingent Debt
39. Optimal Taxation with State-Contingent Debt¶
Contents
In addition to what’s in Anaconda, this lecture will need the following libraries:
!pip install --upgrade quantecon
Requirement already up-to-date: quantecon in /usr/share/miniconda3/envs/quantecon/lib/python3.8/site-packages (0.5.0)
Requirement already satisfied, skipping upgrade: numba>=0.38 in /usr/share/miniconda3/envs/quantecon/lib/python3.8/site-packages (from quantecon) (0.51.2)
Requirement already satisfied, skipping upgrade: numpy in /usr/share/miniconda3/envs/quantecon/lib/python3.8/site-packages (from quantecon) (1.19.2)
Requirement already satisfied, skipping upgrade: requests in /usr/share/miniconda3/envs/quantecon/lib/python3.8/site-packages (from quantecon) (2.24.0)
Requirement already satisfied, skipping upgrade: scipy>=1.0.0 in /usr/share/miniconda3/envs/quantecon/lib/python3.8/site-packages (from quantecon) (1.5.2)
Requirement already satisfied, skipping upgrade: sympy in /usr/share/miniconda3/envs/quantecon/lib/python3.8/site-packages (from quantecon) (1.6.2)
Requirement already satisfied, skipping upgrade: llvmlite<0.35,>=0.34.0.dev0 in /usr/share/miniconda3/envs/quantecon/lib/python3.8/site-packages (from numba>=0.38->quantecon) (0.34.0)
Requirement already satisfied, skipping upgrade: setuptools in /usr/share/miniconda3/envs/quantecon/lib/python3.8/site-packages (from numba>=0.38->quantecon) (50.3.1.post20201107)
Requirement already satisfied, skipping upgrade: chardet<4,>=3.0.2 in /usr/share/miniconda3/envs/quantecon/lib/python3.8/site-packages (from requests->quantecon) (3.0.4)
Requirement already satisfied, skipping upgrade: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/share/miniconda3/envs/quantecon/lib/python3.8/site-packages (from requests->quantecon) (1.25.11)
Requirement already satisfied, skipping upgrade: certifi>=2017.4.17 in /usr/share/miniconda3/envs/quantecon/lib/python3.8/site-packages (from requests->quantecon) (2020.6.20)
Requirement already satisfied, skipping upgrade: idna<3,>=2.5 in /usr/share/miniconda3/envs/quantecon/lib/python3.8/site-packages (from requests->quantecon) (2.10)
Requirement already satisfied, skipping upgrade: mpmath>=0.19 in /usr/share/miniconda3/envs/quantecon/lib/python3.8/site-packages (from sympy->quantecon) (1.1.0)
39.1. Overview¶
This lecture describes a celebrated model of optimal fiscal policy by Robert E. Lucas, Jr., and Nancy Stokey [LS83].
The model revisits classic issues about how to pay for a war.
Here a war means a more or less temporary surge in an exogenous government expenditure process.
The model features
a government that must finance an exogenous stream of government expenditures with either
a flat rate tax on labor, or
purchases and sales from a full array of Arrow state-contingent securities
a representative household that values consumption and leisure
a linear production function mapping labor into a single good
a Ramsey planner who at time \(t=0\) chooses a plan for taxes and trades of Arrow securities for all \(t \geq 0\)
After first presenting the model in a space of sequences, we shall represent it recursively in terms of two Bellman equations formulated along lines that we encountered in Dynamic Stackelberg models.
As in Dynamic Stackelberg models, to apply dynamic programming we shall define the state vector artfully.
In particular, we shall include forward-looking variables that summarize optimal responses of private agents to a Ramsey plan.
See Optimal taxation for analysis within a linear-quadratic setting.
Let’s start with some standard imports:
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
39.2. A Competitive Equilibrium with Distorting Taxes¶
At time \(t \geq 0\) a random variable \(s_t\) belongs to a time-invariant set \({\cal S} = [1, 2, \ldots, S]\).
For \(t \geq 0\), a history \(s^t = [s_t, s_{t-1}, \ldots, s_0]\) of an exogenous state \(s_t\) has joint probability density \(\pi_t(s^t)\).
We begin by assuming that government purchases \(g_t(s^t)\) at time \(t \geq 0\) depend on \(s^t\).
Let \(c_t(s^t)\), \(\ell_t(s^t)\), and \(n_t(s^t)\) denote consumption, leisure, and labor supply, respectively, at history \(s^t\) and date \(t\).
A representative household is endowed with one unit of time that can be divided between leisure \(\ell_t\) and labor \(n_t\):
Output equals \(n_t(s^t)\) and can be divided between \(c_t(s^t)\) and \(g_t(s^t)\)
A representative household’s preferences over \(\{c_t(s^t), \ell_t(s^t)\}_{t=0}^\infty\) are ordered by
where the utility function \(u\) is increasing, strictly concave, and three times continuously differentiable in both arguments.
The technology pins down a pre-tax wage rate to unity for all \(t, s^t\).
The government imposes a flat-rate tax \(\tau_t(s^t)\) on labor income at time \(t\), history \(s^t\).
There are complete markets in one-period Arrow securities.
One unit of an Arrow security issued at time \(t\) at history \(s^t\) and promising to pay one unit of time \(t+1\) consumption in state \(s_{t+1}\) costs \(p_{t+1}(s_{t+1}|s^t)\).
The government issues one-period Arrow securities each period.
The government has a sequence of budget constraints whose time \(t \geq 0\) component is
where
\(p_{t+1}(s_{t+1}|s^t)\) is a competitive equilibrium price of one unit of consumption at date \(t+1\) in state \(s_{t+1}\) at date \(t\) and history \(s^t\).
\(b_t(s_t|s^{t-1})\) is government debt falling due at time \(t\), history \(s^t\).
Government debt \(b_0(s_0)\) is an exogenous initial condition.
The representative household has a sequence of budget constraints whose time \(t\geq 0\) component is
A government policy is an exogenous sequence \(\{g(s_t)\}_{t=0}^\infty\), a tax rate sequence \(\{\tau_t(s^t)\}_{t=0}^\infty\), and a government debt sequence \(\{b_{t+1}(s^{t+1})\}_{t=0}^\infty\).
A feasible allocation is a consumption-labor supply plan \(\{c_t(s^t), n_t(s^t)\}_{t=0}^\infty\) that satisfies (39.2) at all \(t, s^t\).
A price system is a sequence of Arrow security prices \(\{p_{t+1}(s_{t+1} | s^t) \}_{t=0}^\infty\).
The household faces the price system as a price-taker and takes the government policy as given.
The household chooses \(\{c_t(s^t), \ell_t(s^t)\}_{t=0}^\infty\) to maximize (39.3) subject to (39.5) and (39.1) for all \(t, s^t\).
A competitive equilibrium with distorting taxes is a feasible allocation, a price system, and a government policy such that
Given the price system and the government policy, the allocation solves the household’s optimization problem.
Given the allocation, government policy, and price system, the government’s budget constraint is satisfied for all \(t, s^t\).
Note: There are many competitive equilibria with distorting taxes.
They are indexed by different government policies.
The Ramsey problem or optimal taxation problem is to choose a competitive equilibrium with distorting taxes that maximizes (39.3).
39.2.1. Arrow-Debreu Version of Price System¶
We find it convenient sometimes to work with the Arrow-Debreu price system that is implied by a sequence of Arrow securities prices.
Let \(q_t^0(s^t)\) be the price at time \(0\), measured in time \(0\) consumption goods, of one unit of consumption at time \(t\), history \(s^t\).
The following recursion relates Arrow-Debreu prices \(\{q_t^0(s^t)\}_{t=0}^\infty\) to Arrow securities prices \(\{p_{t+1}(s_{t+1}|s^t)\}_{t=0}^\infty\)
Arrow-Debreu prices are useful when we want to compress a sequence of budget constraints into a single intertemporal budget constraint, as we shall find it convenient to do below.
39.2.2. Primal Approach¶
We apply a popular approach to solving a Ramsey problem, called the primal approach.
The idea is to use first-order conditions for household optimization to eliminate taxes and prices in favor of quantities, then pose an optimization problem cast entirely in terms of quantities.
After Ramsey quantities have been found, taxes and prices can then be unwound from the allocation.
The primal approach uses four steps:
Obtain first-order conditions of the household’s problem and solve them for \(\{q^0_t(s^t), \tau_t(s^t)\}_{t=0}^\infty\) as functions of the allocation \(\{c_t(s^t), n_t(s^t)\}_{t=0}^\infty\).
Substitute these expressions for taxes and prices in terms of the allocation into the household’s present-value budget constraint.
This intertemporal constraint involves only the allocation and is regarded as an implementability constraint.
Find the allocation that maximizes the utility of the representative household (39.3) subject to the feasibility constraints (39.1) and (39.2) and the implementability condition derived in step 2.
This optimal allocation is called the Ramsey allocation.
Use the Ramsey allocation together with the formulas from step 1 to find taxes and prices.
39.2.3. The Implementability Constraint¶
By sequential substitution of one one-period budget constraint (39.5) into another, we can obtain the household’s present-value budget constraint:
\(\{q^0_t(s^t)\}_{t=1}^\infty\) can be interpreted as a time \(0\) Arrow-Debreu price system.
To approach the Ramsey problem, we study the household’s optimization problem.
First-order conditions for the household’s problem for \(\ell_t(s^t)\) and \(b_t(s_{t+1}| s^t)\), respectively, imply
and
where \(\pi(s_{t+1} | s^t)\) is the probability distribution of \(s_{t+1}\) conditional on history \(s^t\).
Equation (39.9) implies that the Arrow-Debreu price system satisfies
(The stochastic process \(\{q_t^0(s^t)\}\) is an instance of what finance economists call a stochastic discount factor process.)
Using the first-order conditions (39.8) and (39.9) to eliminate taxes and prices from (39.7), we derive the implementability condition
The Ramsey problem is to choose a feasible allocation that maximizes
subject to (39.11).
39.2.4. Solution Details¶
First, define a “pseudo utility function”
where \(\Phi\) is a Lagrange multiplier on the implementability condition (39.7).
Next form the Lagrangian
where \(\{\theta_t(s^t); \forall s^t\}_{t\geq0}\) is a sequence of Lagrange multipliers on the feasible conditions (39.2).
Given an initial government debt \(b_0\), we want to maximize \(J\) with respect to \(\{c_t(s^t), n_t(s^t); \forall s^t \}_{t\geq0}\) and to minimize with respect to \(\Phi\) and with respect to \(\{\theta(s^t); \forall s^t \}_{t\geq0}\).
The first-order conditions for the Ramsey problem for periods \(t \geq 1\) and \(t=0\), respectively, are
and
Please note how these first-order conditions differ between \(t=0\) and \(t \geq 1\).
It is instructive to use first-order conditions (39.15) for \(t \geq 1\) to eliminate the multipliers \(\theta_t(s^t)\).
For convenience, we suppress the time subscript and the index \(s^t\) and obtain
where we have imposed conditions (39.1) and (39.2).
Equation (39.17) is one equation that can be solved to express the unknown \(c\) as a function of the exogenous variable \(g\) and the Lagrange multiplier \(\Phi\).
We also know that time \(t=0\) quantities \(c_0\) and \(n_0\) satisfy
Notice that a counterpart to \(b_0\) does not appear in (39.17), so \(c\) does not directly depend on it for \(t \geq 1\).
But things are different for time \(t=0\).
An analogous argument for the \(t=0\) equations (39.16) leads to one equation that can be solved for \(c_0\) as a function of the pair \((g(s_0), b_0)\) and the Lagrange multiplier \(\Phi\).
These outcomes mean that the following statement would be true even when government purchases are history-dependent functions \(g_t(s^t)\) of the history of \(s^t\).
Proposition: If government purchases are equal after two histories \(s^t\) and \(\tilde s^\tau\) for \(t,\tau\geq0\), i.e., if
then it follows from (39.17) that the Ramsey choices of consumption and leisure, \((c_t(s^t),\ell_t(s^t))\) and \((c_j(\tilde s^\tau),\ell_j(\tilde s^\tau))\), are identical.
The proposition asserts that the optimal allocation is a function of the currently realized quantity of government purchases \(g\) only and does not depend on the specific history that preceded that realization of \(g\).
39.2.5. The Ramsey Allocation for a Given Multiplier¶
Temporarily take \(\Phi\) as given.
We shall compute \(c_0(s^0, b_0)\) and \(n_0(s^0, b_0)\) from the first-order conditions (39.16).
Evidently, for \(t \geq 1\), \(c\) and \(n\) depend on the time \(t\) realization of \(g\) only.
But for \(t=0\), \(c\) and \(n\) depend on both \(g_0\) and the government’s initial debt \(b_0\).
Thus, while \(b_0\) influences \(c_0\) and \(n_0\), there appears no analogous variable \(b_t\) that influences \(c_t\) and \(n_t\) for \(t \geq 1\).
The absence of \(b_t\) as a direct determinant of the Ramsey allocation for \(t \geq 1\) and its presence for \(t=0\) is a symptom of the time-inconsistency of a Ramsey plan.
Of course, \(b_0\) affects the Ramsey allocation for \(t \geq 1\) indirectly through its effect on \(\Phi\).
\(\Phi\) has to take a value that assures that the household and the government’s budget constraints are both satisfied at a candidate Ramsey allocation and price system associated with that \(\Phi\).
39.2.6. Further Specialization¶
At this point, it is useful to specialize the model in the following ways.
We assume that \(s\) is governed by a finite state Markov chain with states \(s\in [1, \ldots, S]\) and transition matrix \(\Pi\), where
Also, assume that government purchases \(g\) are an exact time-invariant function \(g(s)\) of \(s\).
We maintain these assumptions throughout the remainder of this lecture.
39.2.7. Determining the Lagrange Multiplier¶
We complete the Ramsey plan by computing the Lagrange multiplier \(\Phi\) on the implementability constraint (39.11).
Government budget balance restricts \(\Phi\) via the following line of reasoning.
The household’s first-order conditions imply
and the implied one-period Arrow securities prices
Substituting from (39.19), (39.20), and the feasibility condition (39.2) into the recursive version (39.5) of the household budget constraint gives
Define \(x_t(s^t) = u_c(s^t) b_t(s_t | s^{t-1})\).
Notice that \(x_t(s^t)\) appears on the right side of (39.21) while \(\beta\) times the conditional expectation of \(x_{t+1}(s^{t+1})\) appears on the left side.
Hence the equation shares much of the structure of a simple asset pricing equation with \(x_t\) being analogous to the price of the asset at time \(t\).
We learned earlier that for a Ramsey allocation \(c_t(s^t), n_t(s^t)\), and \(b_t(s_t|s^{t-1})\), and therefore also \(x_t(s^t)\), are each functions of \(s_t\) only, being independent of the history \(s^{t-1}\) for \(t \geq 1\).
That means that we can express equation (39.21) as
where \(s'\) denotes a next period value of \(s\) and \(x'(s')\) denotes a next period value of \(x\).
Given \(n(s)\) for \(s = 1, \ldots , S\), equation (39.22) is easy to solve for \(x(s)\) for \(s = 1, \ldots , S\).
If we let \(\vec n, \vec g, \vec x\) denote \(S \times 1\) vectors whose \(i\)th elements are the respective \(n, g\), and \(x\) values when \(s=i\), and let \(\Pi\) be the transition matrix for the Markov state \(s\), then we can express (39.22) as the matrix equation
This is a system of \(S\) linear equations in the \(S \times 1\) vector \(x\), whose solution is
In these equations, by \(\vec u_c \vec n\), for example, we mean element-by-element multiplication of the two vectors.
After solving for \(\vec x\), we can find \(b(s_t|s^{t-1})\) in Markov state \(s_t=s\) from \(b(s) = {\frac{x(s)}{u_c(s)}}\) or the matrix equation
where division here means an element-by-element division of the respective components of the \(S \times 1\) vectors \(\vec x\) and \(\vec u_c\).
Here is a computational algorithm:
Start with a guess for the value for \(\Phi\), then use the first-order conditions and the feasibility conditions to compute \(c(s_t), n(s_t)\) for \(s \in [1,\ldots, S]\) and \(c_0(s_0,b_0)\) and \(n_0(s_0, b_0)\), given \(\Phi\).
these are \(2 (S+1)\) equations in \(2 (S+1)\) unknowns.
Solve the \(S\) equations (39.24) for the \(S\) elements of \(\vec x\).
these depend on \(\Phi\).
Find a \(\Phi\) that satisfies
(39.26)¶\[u_{c,0} b_0 = u_{c,0} (n_0 - g_0) - u_{l,0} n_0 + \beta \sum_{s=1}^S \Pi(s | s_0) x(s)\]by gradually raising \(\Phi\) if the left side of (39.26) exceeds the right side and lowering \(\Phi\) if the left side is less than the right side.
After computing a Ramsey allocation, recover the flat tax rate on labor from (39.8) and the implied one-period Arrow securities prices from (39.9).
In summary, when \(g_t\) is a time-invariant function of a Markov state \(s_t\), a Ramsey plan can be constructed by solving \(3S +3\) equations for \(S\) components each of \(\vec c\), \(\vec n\), and \(\vec x\) together with \(n_0, c_0\), and \(\Phi\).
39.2.8. Time Inconsistency¶
Let \(\{\tau_t(s^t)\}_{t=0}^\infty, \{b_{t+1}(s_{t+1}| s^t)\}_{t=0}^\infty\) be a time \(0\), state \(s_0\) Ramsey plan.
Then \(\{\tau_j(s^j)\}_{j=t}^\infty, \{b_{j+1}(s_{j+1}| s^j)\}_{j=t}^\infty\) is a time \(t\), history \(s^t\) continuation of a time \(0\), state \(s_0\) Ramsey plan.
A time \(t\), history \(s^t\) Ramsey plan is a Ramsey plan that starts from initial conditions \(s^t, b_t(s_t|s^{t-1})\).
A time \(t\), history \(s^t\) continuation of a time \(0\), state \(0\) Ramsey plan is not a time \(t\), history \(s^t\) Ramsey plan.
The means that a Ramsey plan is not time consistent.
Another way to say the same thing is that a Ramsey plan is time inconsistent.
The reason is that a continuation Ramsey plan takes \(u_{ct} b_t(s_t|s^{t-1})\) as given, not \(b_t(s_t|s^{t-1})\).
We shall discuss this more below.
39.2.9. Specification with CRRA Utility¶
In our calculations below and in a subsequent lecture based on an extension of the Lucas-Stokey model by Aiyagari, Marcet, Sargent, and Seppälä (2002) [AMSSeppala02], we shall modify the one-period utility function assumed above.
(We adopted the preceding utility specification because it was the one used in the original Lucas-Stokey paper [LS83]. We shall soon revert to that specification in a subsequent section.)
We will modify their specification by instead assuming that the representative agent has utility function
where \(\sigma > 0\), \(\gamma >0\).
We continue to assume that
We eliminate leisure from the model.
We also eliminate Lucas and Stokey’s restriction that \(\ell_t + n_t \leq 1\).
We replace these two things with the assumption that labor \(n_t \in [0, +\infty]\).
With these adjustments, the analysis of Lucas and Stokey prevails once we make the following replacements
With these understandings, equations (39.17) and (39.18) simplify in the case of the CRRA utility function.
They become
and
In equation (39.27), it is understood that \(c\) and \(g\) are each functions of the Markov state \(s\).
In addition, the time \(t=0\) budget constraint is satisfied at \(c_0\) and initial government debt \(b_0\):
where \(\tau_0\) is the time \(t=0\) tax rate.
In equation (39.29), it is understood that
39.2.10. Sequence Implementation¶
The above steps are implemented in a class called SequentialAllocation
import numpy as np
from scipy.optimize import root
from quantecon import MarkovChain
class SequentialAllocation:
'''
Class that takes CESutility or BGPutility object as input returns
planner's allocation as a function of the multiplier on the
implementability constraint μ.
'''
def __init__(self, model):
# Initialize from model object attributes
self.β, self.π, self.G = model.β, model.π, model.G
self.mc, self.Θ = MarkovChain(self.π), model.Θ
self.S = len(model.π) # Number of states
self.model = model
# Find the first best allocation
self.find_first_best()
def find_first_best(self):
'''
Find the first best allocation
'''
model = self.model
S, Θ, G = self.S, self.Θ, self.G
Uc, Un = model.Uc, model.Un
def res(z):
c = z[:S]
n = z[S:]
return np.hstack([Θ * Uc(c, n) + Un(c, n), Θ * n - c - G])
res = root(res, 0.5 * np.ones(2 * S))
if not res.success:
raise Exception('Could not find first best')
self.cFB = res.x[:S]
self.nFB = res.x[S:]
# Multiplier on the resource constraint
self.ΞFB = Uc(self.cFB, self.nFB)
self.zFB = np.hstack([self.cFB, self.nFB, self.ΞFB])
def time1_allocation(self, μ):
'''
Computes optimal allocation for time t >= 1 for a given μ
'''
model = self.model
S, Θ, G = self.S, self.Θ, self.G
Uc, Ucc, Un, Unn = model.Uc, model.Ucc, model.Un, model.Unn
def FOC(z):
c = z[:S]
n = z[S:2 * S]
Ξ = z[2 * S:]
# FOC of c
return np.hstack([Uc(c, n) - μ * (Ucc(c, n) * c + Uc(c, n)) - Ξ,
Un(c, n) - μ * (Unn(c, n) * n + Un(c, n)) \
+ Θ * Ξ, # FOC of n
Θ * n - c - G])
# Find the root of the first-order condition
res = root(FOC, self.zFB)
if not res.success:
raise Exception('Could not find LS allocation.')
z = res.x
c, n, Ξ = z[:S], z[S:2 * S], z[2 * S:]
# Compute x
I = Uc(c, n) * c + Un(c, n) * n
x = np.linalg.solve(np.eye(S) - self.β * self.π, I)
return c, n, x, Ξ
def time0_allocation(self, B_, s_0):
'''
Finds the optimal allocation given initial government debt B_ and
state s_0
'''
model, π, Θ, G, β = self.model, self.π, self.Θ, self.G, self.β
Uc, Ucc, Un, Unn = model.Uc, model.Ucc, model.Un, model.Unn
# First order conditions of planner's problem
def FOC(z):
μ, c, n, Ξ = z
xprime = self.time1_allocation(μ)[2]
return np.hstack([Uc(c, n) * (c - B_) + Un(c, n) * n + β * π[s_0]
@ xprime,
Uc(c, n) - μ * (Ucc(c, n)
* (c - B_) + Uc(c, n)) - Ξ,
Un(c, n) - μ * (Unn(c, n) * n
+ Un(c, n)) + Θ[s_0] * Ξ,
(Θ * n - c - G)[s_0]])
# Find root
res = root(FOC, np.array(
[0, self.cFB[s_0], self.nFB[s_0], self.ΞFB[s_0]]))
if not res.success:
raise Exception('Could not find time 0 LS allocation.')
return res.x
def time1_value(self, μ):
'''
Find the value associated with multiplier μ
'''
c, n, x, Ξ = self.time1_allocation(μ)
U = self.model.U(c, n)
V = np.linalg.solve(np.eye(self.S) - self.β * self.π, U)
return c, n, x, V
def Τ(self, c, n):
'''
Computes Τ given c, n
'''
model = self.model
Uc, Un = model.Uc(c, n), model.Un(c, n)
return 1 + Un / (self.Θ * Uc)
def simulate(self, B_, s_0, T, sHist=None):
'''
Simulates planners policies for T periods
'''
model, π, β = self.model, self.π, self.β
Uc = model.Uc
if sHist is None:
sHist = self.mc.simulate(T, s_0)
cHist, nHist, Bhist, ΤHist, μHist = np.zeros((5, T))
RHist = np.zeros(T - 1)
# Time 0
μ, cHist[0], nHist[0], _ = self.time0_allocation(B_, s_0)
ΤHist[0] = self.Τ(cHist[0], nHist[0])[s_0]
Bhist[0] = B_
μHist[0] = μ
# Time 1 onward
for t in range(1, T):
c, n, x, Ξ = self.time1_allocation(μ)
Τ = self.Τ(c, n)
u_c = Uc(c, n)
s = sHist[t]
Eu_c = π[sHist[t - 1]] @ u_c
cHist[t], nHist[t], Bhist[t], ΤHist[t] = c[s], n[s], x[s] / u_c[s], \
Τ[s]
RHist[t - 1] = Uc(cHist[t - 1], nHist[t - 1]) / (β * Eu_c)
μHist[t] = μ
return np.array([cHist, nHist, Bhist, ΤHist, sHist, μHist, RHist])
39.3. Recursive Formulation of the Ramsey Problem¶
We now temporarily revert to Lucas and Stokey’s specification.
We start by noting that \(x_t(s^t) = u_c(s^t) b_t(s_t | s^{t-1})\) in equation (39.21) appears to be a purely “forward-looking” variable.
But \(x_t(s^t)\) is a natural candidate for a state variable in a recursive formulation of the Ramsey problem, one that records history-dependence and so is ``backward-looking’’.
39.3.1. Intertemporal Delegation¶
To express a Ramsey plan recursively, we imagine that a time \(0\) Ramsey planner is followed by a sequence of continuation Ramsey planners at times \(t = 1, 2, \ldots\).
A “continuation Ramsey planner” at time \(t \geq 1\) has a different objective function and faces different constraints and state variables than does the Ramsey planner at time \(t =0\).
A key step in representing a Ramsey plan recursively is to regard the marginal utility scaled government debts \(x_t(s^t) = u_c(s^t) b_t(s_t|s^{t-1})\) as predetermined quantities that continuation Ramsey planners at times \(t \geq 1\) are obligated to attain.
Continuation Ramsey planners do this by choosing continuation policies that induce the representative household to make choices that imply that \(u_c(s^t) b_t(s_t|s^{t-1})= x_t(s^t)\).
A time \(t \geq 1\) continuation Ramsey planner faces \(x_t, s_t\) as state variables.
A time \(t\geq 1\) continuation Ramsey planner delivers \(x_t\) by choosing a suitable \(n_t, c_t\) pair and a list of \(s_{t+1}\)-contingent continuation quantities \(x_{t+1}\) to bequeath to a time \(t+1\) continuation Ramsey planner.
While a time \(t \geq 1\) continuation Ramsey planner faces \(x_t, s_t\) as state variables, the time \(0\) Ramsey planner faces \(b_0\), not \(x_0\), as a state variable.
Furthermore, the Ramsey planner cares about \((c_0(s_0), \ell_0(s_0))\), while continuation Ramsey planners do not.
The time \(0\) Ramsey planner hands a state-contingent function that make \(x_1\) a function of \(s_1\) to a time \(1\), state \(s_1\) continuation Ramsey planner.
These lines of delegated authorities and responsibilities across time express the continuation Ramsey planners’ obligations to implement their parts of an original Ramsey plan that had been designed once-and-for-all at time \(0\).
39.3.2. Two Bellman Equations¶
After \(s_t\) has been realized at time \(t \geq 1\), the state variables confronting the time \(t\) continuation Ramsey planner are \((x_t, s_t)\).
Let \(V(x, s)\) be the value of a continuation Ramsey plan at \(x_t = x, s_t =s\) for \(t \geq 1\).
Let \(W(b, s)\) be the value of a Ramsey plan at time \(0\) at \(b_0=b\) and \(s_0 = s\).
We work backward by preparing a Bellman equation for \(V(x,s)\) first, then a Bellman equation for \(W(b,s)\).
39.3.3. The Continuation Ramsey Problem¶
The Bellman equation for a time \(t \geq 1\) continuation Ramsey planner is
where maximization over \(n\) and the \(S\) elements of \(x'(s')\) is subject to the single implementability constraint for \(t \geq 1\):
Here \(u_c\) and \(u_l\) are today’s values of the marginal utilities.
For each given value of \(x, s\), the continuation Ramsey planner chooses \(n\) and \(x'(s')\) for each \(s' \in {\cal S}\).
Associated with a value function \(V(x,s)\) that solves Bellman equation (39.30) are \(S+1\) time-invariant policy functions
39.3.4. The Ramsey Problem¶
The Bellman equation of the time \(0\) Ramsey planner is
where maximization over \(n_0\) and the \(S\) elements of \(x'(s_1)\) is subject to the time \(0\) implementability constraint
coming from restriction (39.26).
Associated with a value function \(W(b_0, n_0)\) that solves Bellman equation (39.33) are \(S +1\) time \(0\) policy functions
Notice the appearance of state variables \((b_0, s_0)\) in the time \(0\) policy functions for the Ramsey planner as compared to \((x_t, s_t)\) in the policy functions (39.32) for the time \(t \geq 1\) continuation Ramsey planners.
The value function \(V(x_t, s_t)\) of the time \(t\) continuation Ramsey planner equals \(E_t \sum_{\tau = t}^\infty \beta^{\tau - t} u(c_\tau, l_\tau)\), where consumption and leisure processes are evaluated along the original time \(0\) Ramsey plan.
39.3.5. First-Order Conditions¶
Attach a Lagrange multiplier \(\Phi_1(x,s)\) to constraint (39.31) and a Lagrange multiplier \(\Phi_0\) to constraint (39.26).
Time \(t \geq 1\): First-order conditions for the time \(t \geq 1\) constrained maximization problem on the right side of the continuation Ramsey planner’s Bellman equation (39.30) are
for \(x'(s')\) and
for \(n\).
Given \(\Phi_1\), equation (39.37) is one equation to be solved for \(n\) as a function of \(s\) (or of \(g(s)\)).
Equation (39.36) implies \(V_x(x', s')= \Phi_1\), while an envelope condition is \(V_x(x,s) = \Phi_1\), so it follows that
Time \(t=0\): For the time \(0\) problem on the right side of the Ramsey planner’s Bellman equation (39.33), first-order conditions are
for \(x(s_1), s_1 \in {\cal S}\), and
Notice similarities and differences between the first-order conditions for \(t \geq 1\) and for \(t=0\).
An additional term is present in (39.40) except in three special cases
\(b_0 = 0\), or
\(u_c\) is constant (i.e., preferences are quasi-linear in consumption), or
initial government assets are sufficiently large to finance all government purchases with interest earnings from those assets so that \(\Phi_0= 0\)
Except in these special cases, the allocation and the labor tax rate as functions of \(s_t\) differ between dates \(t=0\) and subsequent dates \(t \geq 1\).
Naturally, the first-order conditions in this recursive formulation of the Ramsey problem agree with the first-order conditions derived when we first formulated the Ramsey plan in the space of sequences.
39.3.6. State Variable Degeneracy¶
Equations (39.38) and (39.39) imply that \(\Phi_0 = \Phi_1\) and that
for all \(t \geq 1\).
When \(V\) is concave in \(x\), this implies state-variable degeneracy along a Ramsey plan in the sense that for \(t \geq 1\), \(x_t\) will be a time-invariant function of \(s_t\).
Given \(\Phi_0\), this function mapping \(s_t\) into \(x_t\) can be expressed as a vector \(\vec x\) that solves equation (39.34) for \(n\) and \(c\) as functions of \(g\) that are associated with \(\Phi = \Phi_0\).
39.3.7. Manifestations of Time Inconsistency¶
While the marginal utility adjusted level of government debt \(x_t\) is a key state variable for the continuation Ramsey planners at \(t \geq 1\), it is not a state variable at time \(0\).
The time \(0\) Ramsey planner faces \(b_0\), not \(x_0 = u_{c,0} b_0\), as a state variable.
The discrepancy in state variables faced by the time \(0\) Ramsey planner and the time \(t \geq 1\) continuation Ramsey planners captures the differing obligations and incentives faced by the time \(0\) Ramsey planner and the time \(t \geq 1\) continuation Ramsey planners.
The time \(0\) Ramsey planner is obligated to honor government debt \(b_0\) measured in time \(0\) consumption goods.
The time \(0\) Ramsey planner can manipulate the value of government debt as measured by \(u_{c,0} b_0\).
In contrast, time \(t \geq 1\) continuation Ramsey planners are obligated not to alter values of debt, as measured by \(u_{c,t} b_t\), that they inherit from a preceding Ramsey planner or continuation Ramsey planner.
When government expenditures \(g_t\) are a time-invariant function of a Markov state \(s_t\), a Ramsey plan and associated Ramsey allocation feature marginal utilities of consumption \(u_c(s_t)\) that, given \(\Phi\), for \(t \geq 1\) depend only on \(s_t\), but that for \(t=0\) depend on \(b_0\) as well.
This means that \(u_c(s_t)\) will be a time-invariant function of \(s_t\) for \(t \geq 1\), but except when \(b_0 = 0\), a different function for \(t=0\).
This in turn means that prices of one-period Arrow securities \(p_{t+1}(s_{t+1} | s_t) = p(s_{t+1}|s_t)\) will be the same time-invariant functions of \((s_{t+1}, s_t)\) for \(t \geq 1\), but a different function \(p_0(s_1|s_0)\) for \(t=0\), except when \(b_0=0\).
The differences between these time \(0\) and time \(t \geq 1\) objects reflect the Ramsey planner’s incentive to manipulate Arrow security prices and, through them, the value of initial government debt \(b_0\).
39.3.8. Recursive Implementation¶
The above steps are implemented in a class called RecursiveAllocation.
import numpy as np
from scipy.interpolate import UnivariateSpline
from scipy.optimize import fmin_slsqp
from quantecon import MarkovChain
from scipy.optimize import root
class RecursiveAllocation:
'''
Compute the planner's allocation by solving Bellman
equation.
'''
def __init__(self, model, μgrid):
self.β, self.π, self.G = model.β, model.π, model.G
self.mc, self.S = MarkovChain(self.π), len(model.π) # Number of states
self.Θ, self.model, self.μgrid = model.Θ, model, μgrid
# Find the first best allocation
self.solve_time1_bellman()
self.T.time_0 = True # Bellman equation now solves time 0 problem
def solve_time1_bellman(self):
'''
Solve the time 1 Bellman equation for calibration model and initial
grid μgrid0
'''
model, μgrid0 = self.model, self.μgrid
S = len(model.π)
# First get initial fit
pp = SequentialAllocation(model)
c, n, x, V = map(np.vstack, zip(*map(lambda μ: pp.time1_value(μ), μgrid0)))
Vf, cf, nf, xprimef = {}, {}, {}, {}
for s in range(2):
ind = np.argsort(x[:, s]) # Sort x
# Sort arrays according to x
c, n, x, V = c[ind], n[ind], x[ind], V[ind]
cf[s] = UnivariateSpline(x[:, s], c[:, s])
nf[s] = UnivariateSpline(x[:, s], n[:, s])
Vf[s] = UnivariateSpline(x[:, s], V[:, s])
for sprime in range(S):
xprimef[s, sprime] = UnivariateSpline(x[:, s], x[:, s])
policies = [cf, nf, xprimef]
# Create xgrid
xbar = [x.min(0).max(), x.max(0).min()]
xgrid = np.linspace(xbar[0], xbar[1], len(μgrid0))
self.xgrid = xgrid
# Now iterate on bellman equation
T = BellmanEquation(model, xgrid, policies)
diff = 1
while diff > 1e-7:
PF = T(Vf)
Vfnew, policies = self.fit_policy_function(PF)
diff = 0
for s in range(S):
diff = max(diff, np.abs(
(Vf[s](xgrid) - Vfnew[s](xgrid)) / Vf[s](xgrid)).max())
Vf = Vfnew
# Store value function policies and Bellman Equations
self.Vf = Vf
self.policies = policies
self.T = T
def fit_policy_function(self, PF):
'''
Fits the policy functions PF using the points xgrid using
UnivariateSpline
'''
xgrid, S = self.xgrid, self.S
Vf, cf, nf, xprimef = {}, {}, {}, {}
for s in range(S):
PFvec = np.vstack(tuple(map(lambda x: PF(x, s), xgrid)))
Vf[s] = UnivariateSpline(xgrid, PFvec[:, 0], s=0)
cf[s] = UnivariateSpline(xgrid, PFvec[:, 1], s=0, k=1)
nf[s] = UnivariateSpline(xgrid, PFvec[:, 2], s=0, k=1)
for sprime in range(S):
xprimef[s, sprime] = UnivariateSpline(
xgrid, PFvec[:, 3 + sprime], s=0, k=1)
return Vf, [cf, nf, xprimef]
def Τ(self, c, n):
'''
Computes Τ given c, n
'''
model = self.model
Uc, Un = model.Uc(c, n), model.Un(c, n)
return 1 + Un / (self.Θ * Uc)
def time0_allocation(self, B_, s0):
'''
Finds the optimal allocation given initial government debt B_ and
state s_0
'''
PF = self.T(self.Vf)
z0 = PF(B_, s0)
c0, n0, xprime0 = z0[1], z0[2], z0[3:]
return c0, n0, xprime0
def simulate(self, B_, s_0, T, sHist=None):
'''
Simulates Ramsey plan for T periods
'''
model, π = self.model, self.π
Uc = model.Uc
cf, nf, xprimef = self.policies
if sHist is None:
sHist = self.mc.simulate(T, s_0)
cHist, nHist, Bhist, ΤHist, μHist = np.zeros((5, T))
RHist = np.zeros(T - 1)
# Time 0
cHist[0], nHist[0], xprime = self.time0_allocation(B_, s_0)
ΤHist[0] = self.Τ(cHist[0], nHist[0])[s_0]
Bhist[0] = B_
μHist[0] = 0
# Time 1 onward
for t in range(1, T):
s, x = sHist[t], xprime[sHist[t]]
c, n, xprime = np.empty(self.S), nf[s](x), np.empty(self.S)
for shat in range(self.S):
c[shat] = cf[shat](x)
for sprime in range(self.S):
xprime[sprime] = xprimef[s, sprime](x)
Τ = self.Τ(c, n)[s]
u_c = Uc(c, n)
Eu_c = π[sHist[t - 1]] @ u_c
μHist[t] = self.Vf[s](x, 1)
RHist[t - 1] = Uc(cHist[t - 1], nHist[t - 1]) / (self.β * Eu_c)
cHist[t], nHist[t], Bhist[t], ΤHist[t] = c[s], n, x / u_c[s], Τ
return np.array([cHist, nHist, Bhist, ΤHist, sHist, μHist, RHist])
class BellmanEquation:
'''
Bellman equation for the continuation of the Lucas-Stokey Problem
'''
def __init__(self, model, xgrid, policies0):
self.β, self.π, self.G = model.β, model.π, model.G
self.S = len(model.π) # Number of states
self.Θ, self.model = model.Θ, model
self.xbar = [min(xgrid), max(xgrid)]
self.time_0 = False
self.z0 = {}
cf, nf, xprimef = policies0
for s in range(self.S):
for x in xgrid:
xprime0 = np.empty(self.S)
for sprime in range(self.S):
xprime0[sprime] = xprimef[s, sprime](x)
self.z0[x, s] = np.hstack([cf[s](x), nf[s](x), xprime0])
self.find_first_best()
def find_first_best(self):
'''
Find the first best allocation
'''
model = self.model
S, Θ, Uc, Un, G = self.S, self.Θ, model.Uc, model.Un, self.G
def res(z):
c = z[:S]
n = z[S:]
return np.hstack([Θ * Uc(c, n) + Un(c, n), Θ * n - c - G])
res = root(res, 0.5 * np.ones(2 * S))
if not res.success:
raise Exception('Could not find first best')
self.cFB = res.x[:S]
self.nFB = res.x[S:]
IFB = Uc(self.cFB, self.nFB) * self.cFB + Un(self.cFB, self.nFB) * self.nFB
self.xFB = np.linalg.solve(np.eye(S) - self.β * self.π, IFB)
self.zFB = {}
for s in range(S):
self.zFB[s] = np.hstack([self.cFB[s], self.nFB[s], self.xFB])
def __call__(self, Vf):
'''
Given continuation value function, next period return value function,
this period return T(V) and optimal policies
'''
if not self.time_0:
def PF(x, s): return self.get_policies_time1(x, s, Vf)
else:
def PF(B_, s0): return self.get_policies_time0(B_, s0, Vf)
return PF
def get_policies_time1(self, x, s, Vf):
'''
Finds the optimal policies
'''
model, β, Θ, = self.model, self.β, self.Θ,
G, S, π = self.G, self.S, self.π
U, Uc, Un = model.U, model.Uc, model.Un
def objf(z):
c, n, xprime = z[0], z[1], z[2:]
Vprime = np.empty(S)
for sprime in range(S):
Vprime[sprime] = Vf[sprime](xprime[sprime])
return -(U(c, n) + β * π[s] @ Vprime)
def cons(z):
c, n, xprime = z[0], z[1], z[2:]
return np.hstack([x - Uc(c, n) * c - Un(c, n) * n - β * π[s]
@ xprime,
(Θ * n - c - G)[s]])
out, fx, _, imode, smode = fmin_slsqp(objf,
self.z0[x, s],
f_eqcons=cons,
bounds=[(0, 100), (0, 100)]
+ [self.xbar] * S,
full_output=True,
iprint=0,
acc=1e-10)
if imode > 0:
raise Exception(smode)
self.z0[x, s] = out
return np.hstack([-fx, out])
def get_policies_time0(self, B_, s0, Vf):
'''
Finds the optimal policies
'''
model, β, Θ, = self.model, self.β, self.Θ,
G, S, π = self.G, self.S, self.π
U, Uc, Un = model.U, model.Uc, model.Un
def objf(z):
c, n, xprime = z[0], z[1], z[2:]
Vprime = np.empty(S)
for sprime in range(S):
Vprime[sprime] = Vf[sprime](xprime[sprime])
return -(U(c, n) + β * π[s0] @ Vprime)
def cons(z):
c, n, xprime = z[0], z[1], z[2:]
return np.hstack([-Uc(c, n) * (c - B_) - Un(c, n) * n - β * π[s0]
@ xprime,
(Θ * n - c - G)[s0]])
out, fx, _, imode, smode = fmin_slsqp(objf, self.zFB[s0], f_eqcons=cons,
bounds=[(0, 100), (0, 100)]
+ [self.xbar] * S,
full_output=True, iprint=0,
acc=1e-10)
if imode > 0:
raise Exception(smode)
return np.hstack([-fx, out])
39.4. Examples¶
We return to the setup with CRRA preferences described above.
39.4.1. Anticipated One-Period War¶
This example illustrates in a simple setting how a Ramsey planner manages risk.
Government expenditures are known for sure in all periods except one
For \(t<3\) and \(t > 3\) we assume that \(g_t = g_l = 0.1\).
At \(t = 3\) a war occurs with probability 0.5.
If there is war, \(g_3 = g_h = 0.2\)
If there is no war \(g_3 = g_l = 0.1\)
We define the components of the state vector as the following six \((t,g)\) pairs: \((0,g_l),(1,g_l),(2,g_l),(3,g_l),(3,g_h), (t\geq 4,g_l)\).
We think of these 6 states as corresponding to \(s=1,2,3,4,5,6\).
The transition matrix is
Government expenditures at each state are
We assume that the representative agent has utility function
and set \(\sigma = 2\), \(\gamma = 2\), and the discount factor \(\beta = 0.9\).
Note: For convenience in terms of matching our code, we have expressed utility as a function of \(n\) rather than leisure \(l\).
This utility function is implemented in the class CRRAutility.
import numpy as np
class CRRAutility:
def __init__(self,
β=0.9,
σ=2,
γ=2,
π=0.5*np.ones((2, 2)),
G=np.array([0.1, 0.2]),
Θ=np.ones(2),
transfers=False):
self.β, self.σ, self.γ = β, σ, γ
self.π, self.G, self.Θ, self.transfers = π, G, Θ, transfers
# Utility function
def U(self, c, n):
σ = self.σ
if σ == 1.:
U = np.log(c)
else:
U = (c**(1 - σ) - 1) / (1 - σ)
return U - n**(1 + self.γ) / (1 + self.γ)
# Derivatives of utility function
def Uc(self, c, n):
return c**(-self.σ)
def Ucc(self, c, n):
return -self.σ * c**(-self.σ - 1)
def Un(self, c, n):
return -n**self.γ
def Unn(self, c, n):
return -self.γ * n**(self.γ - 1)
We set initial government debt \(b_0 = 1\).
We can now plot the Ramsey tax under both realizations of time \(t = 3\) government expenditures
black when \(g_3 = .1\), and
red when \(g_3 = .2\)
time_π = np.array([[0, 1, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0],
[0, 0, 0, 0.5, 0.5, 0],
[0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 0, 1]])
time_G = np.array([0.1, 0.1, 0.1, 0.2, 0.1, 0.1])
# Θ can in principle be random
time_Θ = np.ones(6)
time_example = CRRAutility(π=time_π, G=time_G, Θ=time_Θ)
# Solve sequential problem
time_allocation = SequentialAllocation(time_example)
sHist_h = np.array([0, 1, 2, 3, 5, 5, 5])
sHist_l = np.array([0, 1, 2, 4, 5, 5, 5])
sim_seq_h = time_allocation.simulate(1, 0, 7, sHist_h)
sim_seq_l = time_allocation.simulate(1, 0, 7, sHist_l)
# Government spending paths
sim_seq_l[4] = time_example.G[sHist_l]
sim_seq_h[4] = time_example.G[sHist_h]
# Output paths
sim_seq_l[5] = time_example.Θ[sHist_l] * sim_seq_l[1]
sim_seq_h[5] = time_example.Θ[sHist_h] * sim_seq_h[1]
fig, axes = plt.subplots(3, 2, figsize=(14, 10))
titles = ['Consumption', 'Labor Supply', 'Government Debt',
'Tax Rate', 'Government Spending', 'Output']
for ax, title, sim_l, sim_h in zip(axes.flatten(),
titles, sim_seq_l, sim_seq_h):
ax.set(title=title)
ax.plot(sim_l, '-ok', sim_h, '-or', alpha=0.7)
ax.grid()
plt.tight_layout()
plt.show()
<ipython-input-3-a51c7f9fbc0d>:158: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
return np.array([cHist, nHist, Bhist, ΤHist, sHist, μHist, RHist])
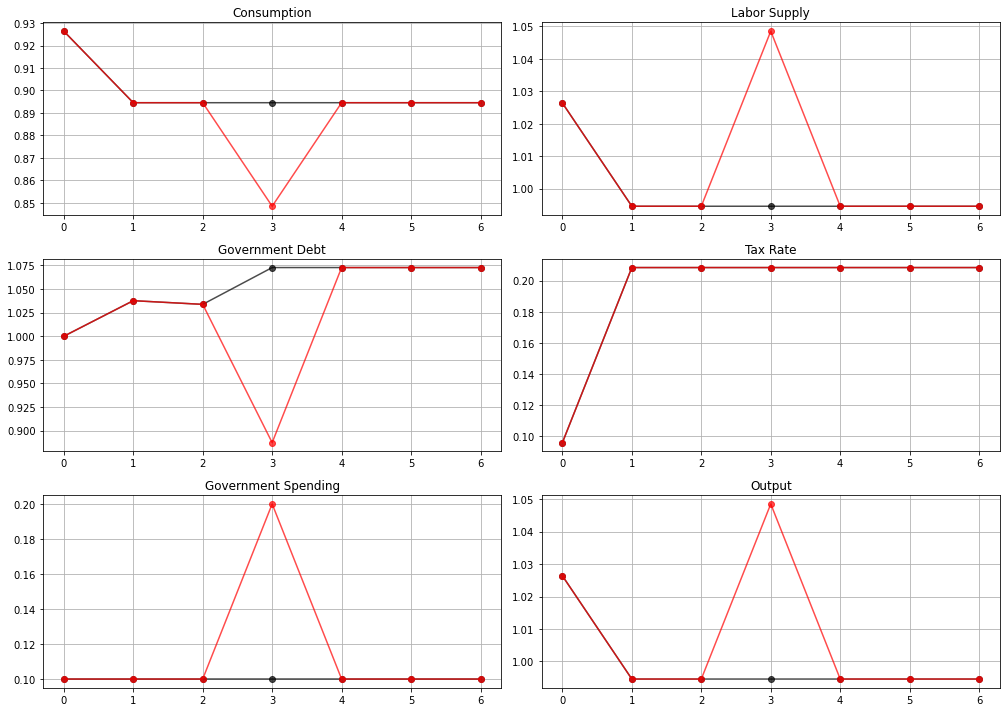
Tax smoothing
the tax rate is constant for all \(t\geq 1\)
For \(t \geq 1, t \neq 3\), this is a consequence of \(g_t\) being the same at all those dates.
For \(t = 3\), it is a consequence of the special one-period utility function that we have assumed.
Under other one-period utility functions, the time \(t=3\) tax rate could be either higher or lower than for dates \(t \geq 1, t \neq 3\).
the tax rate is the same at \(t=3\) for both the high \(g_t\) outcome and the low \(g_t\) outcome
We have assumed that at \(t=0\), the government owes positive debt \(b_0\).
It sets the time \(t=0\) tax rate partly with an eye to reducing the value \(u_{c,0} b_0\) of \(b_0\).
It does this by increasing consumption at time \(t=0\) relative to consumption in later periods.
This has the consequence of lowering the time \(t=0\) value of the gross interest rate for risk-free loans between periods \(t\) and \(t+1\), which equals
A tax policy that makes time \(t=0\) consumption be higher than time \(t=1\) consumption evidently decreases the risk-free rate one-period interest rate, \(R_t\), at \(t=0\).
Lowering the time \(t=0\) risk-free interest rate makes time \(t=0\) consumption goods cheaper relative to consumption goods at later dates, thereby lowering the value \(u_{c,0} b_0\) of initial government debt \(b_0\).
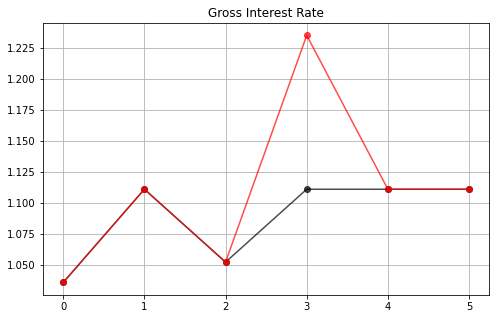
We see this in a figure below that plots the time path for the risk-free interest rate under both realizations of the time \(t=3\) government expenditure shock.
The following plot illustrates how the government lowers the interest rate at time 0 by raising consumption
fix, ax = plt.subplots(figsize=(8, 5))
ax.set_title('Gross Interest Rate')
ax.plot(sim_seq_l[-1], '-ok', sim_seq_h[-1], '-or', alpha=0.7)
ax.grid()
plt.show()
39.4.2. Government Saving¶
At time \(t=0\) the government evidently dissaves since \(b_1> b_0\).
This is a consequence of it setting a lower tax rate at \(t=0\), implying more consumption at \(t=0\).
At time \(t=1\), the government evidently saves since it has set the tax rate sufficiently high to allow it to set \(b_2 < b_1\).
Its motive for doing this is that it anticipates a likely war at \(t=3\).
At time \(t=2\) the government trades state-contingent Arrow securities to hedge against war at \(t=3\).
It purchases a security that pays off when \(g_3 = g_h\).
It sells a security that pays off when \(g_3 = g_l\).
These purchases are designed in such a way that regardless of whether or not there is a war at \(t=3\), the government will begin period \(t=4\) with the same government debt.
The time \(t=4\) debt level can be serviced with revenues from the constant tax rate set at times \(t\geq 1\).
At times \(t \geq 4\) the government rolls over its debt, knowing that the tax rate is set at a level that raises enough revenue to pay for government purchases and interest payments on its debt.
39.4.3. Time 0 Manipulation of Interest Rate¶
We have seen that when \(b_0>0\), the Ramsey plan sets the time \(t=0\) tax rate partly with an eye toward lowering a risk-free interest rate for one-period loans between times \(t=0\) and \(t=1\).
By lowering this interest rate, the plan makes time \(t=0\) goods cheap relative to consumption goods at later times.
By doing this, it lowers the value of time \(t=0\) debt that it has inherited and must finance.
39.4.4. Time 0 and Time-Inconsistency¶
In the preceding example, the Ramsey tax rate at time 0 differs from its value at time 1.
To explore what is going on here, let’s simplify things by removing the possibility of war at time \(t=3\).
The Ramsey problem then includes no randomness because \(g_t = g_l\) for all \(t\).
The figure below plots the Ramsey tax rates and gross interest rates at time \(t=0\) and time \(t\geq1\) as functions of the initial government debt (using the sequential allocation solution and a CRRA utility function defined above)
tax_sequence = SequentialAllocation(CRRAutility(G=0.15,
π=np.ones((1, 1)),
Θ=np.ones(1)))
n = 100
tax_policy = np.empty((n, 2))
interest_rate = np.empty((n, 2))
gov_debt = np.linspace(-1.5, 1, n)
for i in range(n):
tax_policy[i] = tax_sequence.simulate(gov_debt[i], 0, 2)[3]
interest_rate[i] = tax_sequence.simulate(gov_debt[i], 0, 3)[-1]
fig, axes = plt.subplots(2, 1, figsize=(10,8), sharex=True)
titles = ['Tax Rate', 'Gross Interest Rate']
for ax, title, plot in zip(axes, titles, [tax_policy, interest_rate]):
ax.plot(gov_debt, plot[:, 0], gov_debt, plot[:, 1], lw=2)
ax.set(title=title, xlim=(min(gov_debt), max(gov_debt)))
ax.grid()
axes[0].legend(('Time $t=0$', 'Time $t \geq 1$'))
axes[1].set_xlabel('Initial Government Debt')
fig.tight_layout()
plt.show()
<ipython-input-3-a51c7f9fbc0d>:158: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
return np.array([cHist, nHist, Bhist, ΤHist, sHist, μHist, RHist])
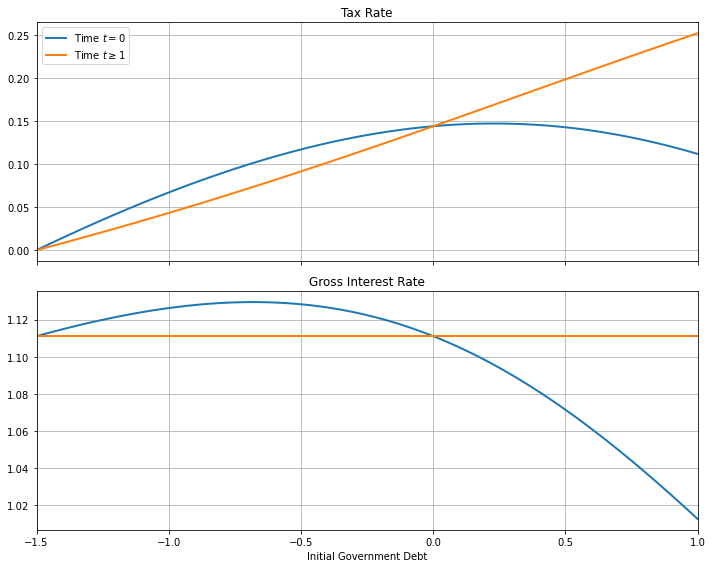
The figure indicates that if the government enters with positive debt, it sets a tax rate at \(t=0\) that is less than all later tax rates.
By setting a lower tax rate at \(t = 0\), the government raises consumption, which reduces the value \(u_{c,0} b_0\) of its initial debt.
It does this by increasing \(c_0\) and thereby lowering \(u_{c,0}\).
Conversely, if \(b_{0} < 0\), the Ramsey planner sets the tax rate at \(t=0\) higher than in subsequent periods.
A side effect of lowering time \(t=0\) consumption is that it lowers the one-period interest rate at time \(t=0\) below that of subsequent periods.
There are only two values of initial government debt at which the tax rate is constant for all \(t \geq 0\).
The first is \(b_{0} = 0\)
Here the government can’t use the \(t=0\) tax rate to alter the value of the initial debt.
The second occurs when the government enters with sufficiently large assets that the Ramsey planner can achieve first best and sets \(\tau_t = 0\) for all \(t\).
It is only for these two values of initial government debt that the Ramsey plan is time-consistent.
Another way of saying this is that, except for these two values of initial government debt, a continuation of a Ramsey plan is not a Ramsey plan.
To illustrate this, consider a Ramsey planner who starts with an initial government debt \(b_1\) associated with one of the Ramsey plans computed above.
Call \(\tau_1^R\) the time \(t=0\) tax rate chosen by the Ramsey planner confronting this value for initial government debt government.
The figure below shows both the tax rate at time 1 chosen by our original Ramsey planner and what a new Ramsey planner would choose for its time \(t=0\) tax rate
tax_sequence = SequentialAllocation(CRRAutility(G=0.15,
π=np.ones((1, 1)),
Θ=np.ones(1)))
n = 100
tax_policy = np.empty((n, 2))
τ_reset = np.empty((n, 2))
gov_debt = np.linspace(-1.5, 1, n)
for i in range(n):
tax_policy[i] = tax_sequence.simulate(gov_debt[i], 0, 2)[3]
τ_reset[i] = tax_sequence.simulate(gov_debt[i], 0, 1)[3]
fig, ax = plt.subplots(figsize=(10, 6))
ax.plot(gov_debt, tax_policy[:, 1], gov_debt, τ_reset, lw=2)
ax.set(xlabel='Initial Government Debt', title='Tax Rate',
xlim=(min(gov_debt), max(gov_debt)))
ax.legend((r'$\tau_1$', r'$\tau_1^R$'))
ax.grid()
fig.tight_layout()
plt.show()
<ipython-input-3-a51c7f9fbc0d>:158: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
return np.array([cHist, nHist, Bhist, ΤHist, sHist, μHist, RHist])
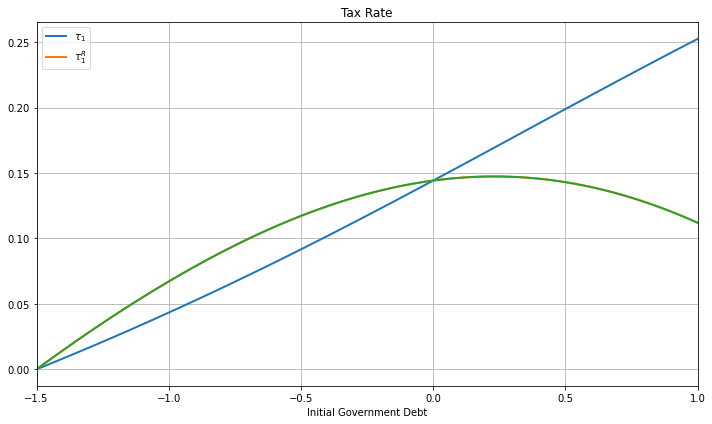
The tax rates in the figure are equal for only two values of initial government debt.
39.4.5. Tax Smoothing and non-CRRA Preferences¶
The complete tax smoothing for \(t \geq 1\) in the preceding example is a consequence of our having assumed CRRA preferences.
To see what is driving this outcome, we begin by noting that the Ramsey tax rate for \(t\geq 1\) is a time-invariant function \(\tau(\Phi,g)\) of the Lagrange multiplier on the implementability constraint and government expenditures.
For CRRA preferences, we can exploit the relations \(U_{cc}c = -\sigma U_c\) and \(U_{nn} n = \gamma U_n\) to derive
from the first-order conditions.
This equation immediately implies that the tax rate is constant.
For other preferences, the tax rate may not be constant.
For example, let the period utility function be
We will create a new class LogUtility to represent this utility function
import numpy as np
class LogUtility:
def __init__(self,
β=0.9,
ψ=0.69,
π=0.5*np.ones((2, 2)),
G=np.array([0.1, 0.2]),
Θ=np.ones(2),
transfers=False):
self.β, self.ψ, self.π = β, ψ, π
self.G, self.Θ, self.transfers = G, Θ, transfers
# Utility function
def U(self, c, n):
return np.log(c) + self.ψ * np.log(1 - n)
# Derivatives of utility function
def Uc(self, c, n):
return 1 / c
def Ucc(self, c, n):
return -c**(-2)
def Un(self, c, n):
return -self.ψ / (1 - n)
def Unn(self, c, n):
return -self.ψ / (1 - n)**2
Also, suppose that \(g_t\) follows a two-state IID process with equal probabilities attached to \(g_l\) and \(g_h\).
To compute the tax rate, we will use both the sequential and recursive approaches described above.
The figure below plots a sample path of the Ramsey tax rate
log_example = LogUtility()
# Solve sequential problem
seq_log = SequentialAllocation(log_example)
# Initialize grid for value function iteration and solve
μ_grid = np.linspace(-0.6, 0.0, 200)
# Solve recursive problem
bel_log = RecursiveAllocation(log_example, μ_grid)
T = 20
sHist = np.array([0, 0, 0, 0, 0, 0, 0,
0, 1, 1, 0, 0, 0, 1,
1, 1, 1, 1, 1, 0])
# Simulate
sim_seq = seq_log.simulate(0.5, 0, T, sHist)
sim_bel = bel_log.simulate(0.5, 0, T, sHist)
# Government spending paths
sim_seq[4] = log_example.G[sHist]
sim_bel[4] = log_example.G[sHist]
# Output paths
sim_seq[5] = log_example.Θ[sHist] * sim_seq[1]
sim_bel[5] = log_example.Θ[sHist] * sim_bel[1]
fig, axes = plt.subplots(3, 2, figsize=(14, 10))
titles = ['Consumption', 'Labor Supply', 'Government Debt',
'Tax Rate', 'Government Spending', 'Output']
for ax, title, sim_s, sim_b in zip(axes.flatten(), titles, sim_seq, sim_bel):
ax.plot(sim_s, '-ob', sim_b, '-xk', alpha=0.7)
ax.set(title=title)
ax.grid()
axes.flatten()[0].legend(('Sequential', 'Recursive'))
fig.tight_layout()
plt.show()
<ipython-input-3-a51c7f9fbc0d>:158: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
return np.array([cHist, nHist, Bhist, ΤHist, sHist, μHist, RHist])
<ipython-input-10-0cc001bf9680>:18: RuntimeWarning: divide by zero encountered in log
return np.log(c) + self.ψ * np.log(1 - n)
<ipython-input-10-0cc001bf9680>:22: RuntimeWarning: divide by zero encountered in double_scalars
return 1 / c
<ipython-input-4-fd6f955ecfcf>:152: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
return np.array([cHist, nHist, Bhist, ΤHist, sHist, μHist, RHist])
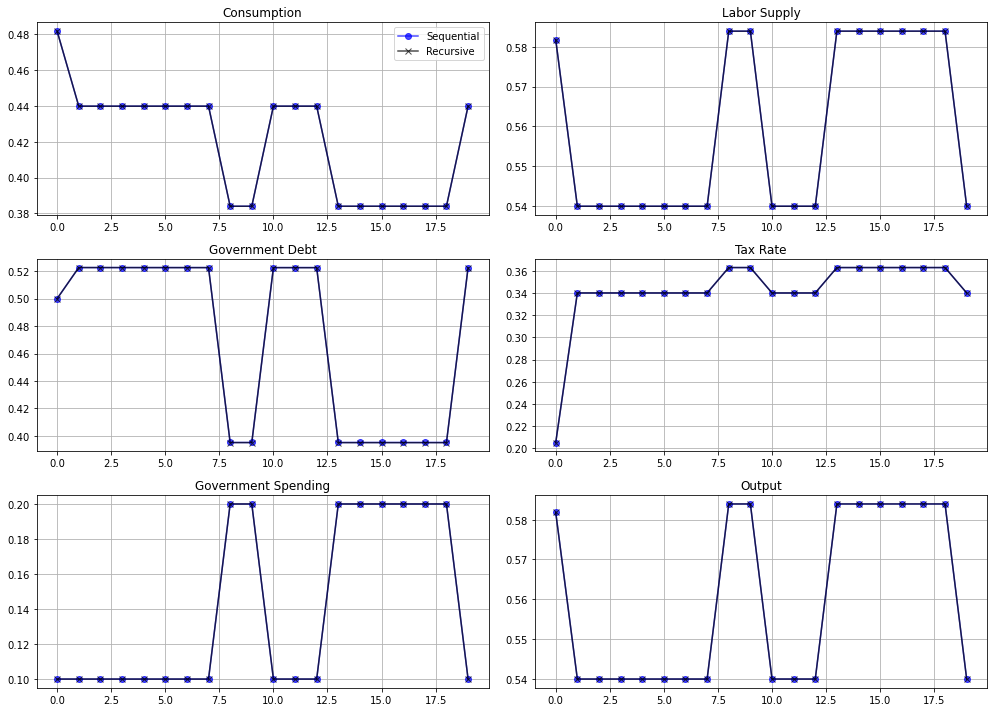
As should be expected, the recursive and sequential solutions produce almost identical allocations.
Unlike outcomes with CRRA preferences, the tax rate is not perfectly smoothed.
Instead, the government raises the tax rate when \(g_t\) is high.
39.4.6. Further Comments¶
A related lecture describes an extension of the Lucas-Stokey model by Aiyagari, Marcet, Sargent, and Seppälä (2002) [AMSSeppala02].
In the AMSS economy, only a risk-free bond is traded.
That lecture compares the recursive representation of the Lucas-Stokey model presented in this lecture with one for an AMSS economy.
By comparing these recursive formulations, we shall glean a sense in which the dimension of the state is lower in the Lucas Stokey model.
Accompanying that difference in dimension will be different dynamics of government debt.